Handoff: Designing AI-to-Human Decision Escalation
AI systems that never admit uncertainty cause more harm than ones that ask for help. This is a framework for deciding when AI should act and when it should escalate.
Role & Responsibilities
- AI Product & UX Design
- Interaction Design & UX Systems
- Trust, Risk & Escalation Design
- Conceptual Prototyping
- Cross-functional Collaboration (Product, Engineering, Data)
Project Goal
Explore how AI and humans can share decision-making in high-stakes workflows while maintaining user control. The project examines how design patterns around confidence signals, escalation pathways, and user override capabilities can reduce decision friction and accelerate time to resolution while keeping users in the loop and respecting their anxiety around AI-made decisions.
The project uses customer support as a familiar context to prototype conceptual UX patterns for safer AI-assisted decisions.
Project Constraints
This project was intentionally designed within the following constraints:
- •Conceptual work only. No access to real customer data, production models, or live support environments.
- •Model-agnostic by design. Assumes varying LLM capabilities and avoids reliance on a single provider.
- •Human accountability required. Final decisions remain with agents due to legal, operational, and trust considerations common in customer support.
- •Agent-facing scope only. Focused on internal decision-making tools, not customer-facing automation.
- •Decision clarity over maximum automation. Optimised for safe, explainable decisions rather than full AI autonomy.
Why This Exists
- •AI tools are increasingly involved in real decisions. Drafting customer replies. Suggesting code. Flagging risks.
- •But confidence alone doesn't tell people when it's safe to act.
- •I created Handoff to explore a question I kept seeing across AI products.
How should systems decide when AI can act independently, when humans should review, and when escalation is required?
I used customer support as the primary context because it’s widely understood and directly relevant to many companies building AI-assisted support workflows, such as Intercom, Zendesk, and similar customer service platforms where AI must decide when to respond, defer, or escalate. The patterns here apply anywhere AI assists humans with decisions that carry real consequences.
This is a conceptual project, grounded in public documentation, real workflows, and observed patterns. The goal wasn't to design a "perfect AI," but to design a system that helps humans make better judgment calls.
The Problem
Support teams are under pressure to move faster without eroding trust.
AI helps by drafting responses, but it introduces new tensions:
- •If AI is wrong, customer trust erodes
- •If agents review everything, efficiency disappears
- •If AI hides uncertainty, agents can't assess risk
The core challenge isn't speed or accuracy in isolation. It's helping humans decide, quickly and safely. Is this response good enough to send, does it need review, or should it escalate?
Design Principle: AI Suggests, Humans Decide
One principle shaped every decision in this system.
AI is a tool, not a decision-maker.
- •AI drafts responses, but agents send them
- •AI flags uncertainty, but agents interpret it
- •AI recommends escalation, but agents confirm it
This preserves accountability, builds trust gradually, and respects human expertise. It also reflects real operational and legal constraints. In many customer-facing or regulated environments, responsibility can't sit with an automated system. Someone has to own the outcome.
Everything that follows is designed around that reality.
The Non-Obvious Insight: Stakes Matter More Than Confidence
Most AI tools treat confidence as the primary signal for action. I started there too.
But looking at real support behavior across products like Intercom Fin and Zendesk AI revealed something different.
Agents don't escalate because AI is uncertain. They escalate because the stakes are high.
Example 1: Low stakes
"Where's my order?" AI confidence: 65%. Action: Sent anyway (low stakes, easy to correct)
Example 2: High stakes
"Can I get a refund after 30 days?" AI confidence: 92%. Action: Reviewed carefully (policy and revenue impact)
A wrong answer to a low-stakes question is an annoyance. A wrong answer to a high-stakes question is a crisis.
This shifted the design from a single axis (confidence) to a two-axis system - Confidence and stakes.
Decision Framework
AI behavior varies along two dimensions:
AI confidence Based on source reliability and answer consistency.
Question stakes Inferred from cost impact and reversibility.
| Low Stakes | High Stakes | |
|---|---|---|
| High Confidence | Auto-send | Suggest with review |
| Low Confidence | Flag for review | Escalate immediately |
This framework doesn't just explain behavior. It directly drives the interface.
How the Framework Drives the Interface
The system evaluates confidence and question type in real time to determine the UI state.
Customer asks:
"Can I get a refund for my annual plan?"
System evaluation:
- •AI confidence: High (clear policy, consistent past answers)
- •Question type: Billing (financial and policy impact)
- •Resulting mode: Suggest with review
UI changes:
- •No default action. Send, Edit, and Escalate have equal weight
- •Reasoning preview is visible
- •Subtle prompt: "Billing question. Review recommended."
AI is likely correct, but the cost of being wrong is high. The interface forces a conscious decision without removing agency.
How AI Action Is Scoped
The system doesn't treat all AI output the same. Its authority changes based on the cost of being wrong.
When confidence is high and the question is low risk, the AI can respond immediately. Speed matters more than precision, and mistakes are easy to correct.
When confidence is high but stakes increase, the AI drafts a response instead of sending it. The agent decides whether to send, edit, or escalate.
When confidence is low or judgement is required, escalation becomes the safest default.
This keeps automation fast where it's safe, and deliberately slower where errors carry real consequences.
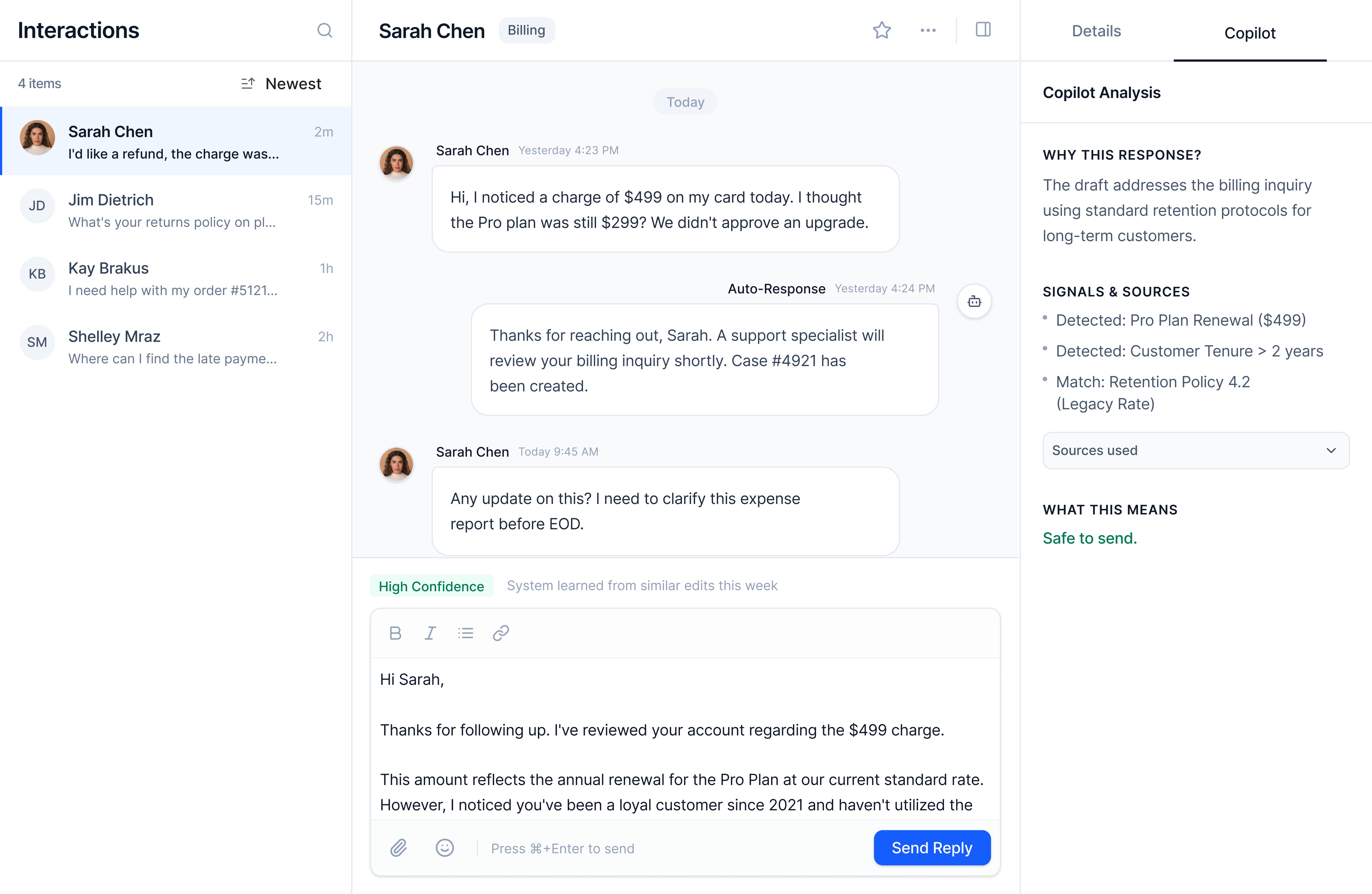
The Interface
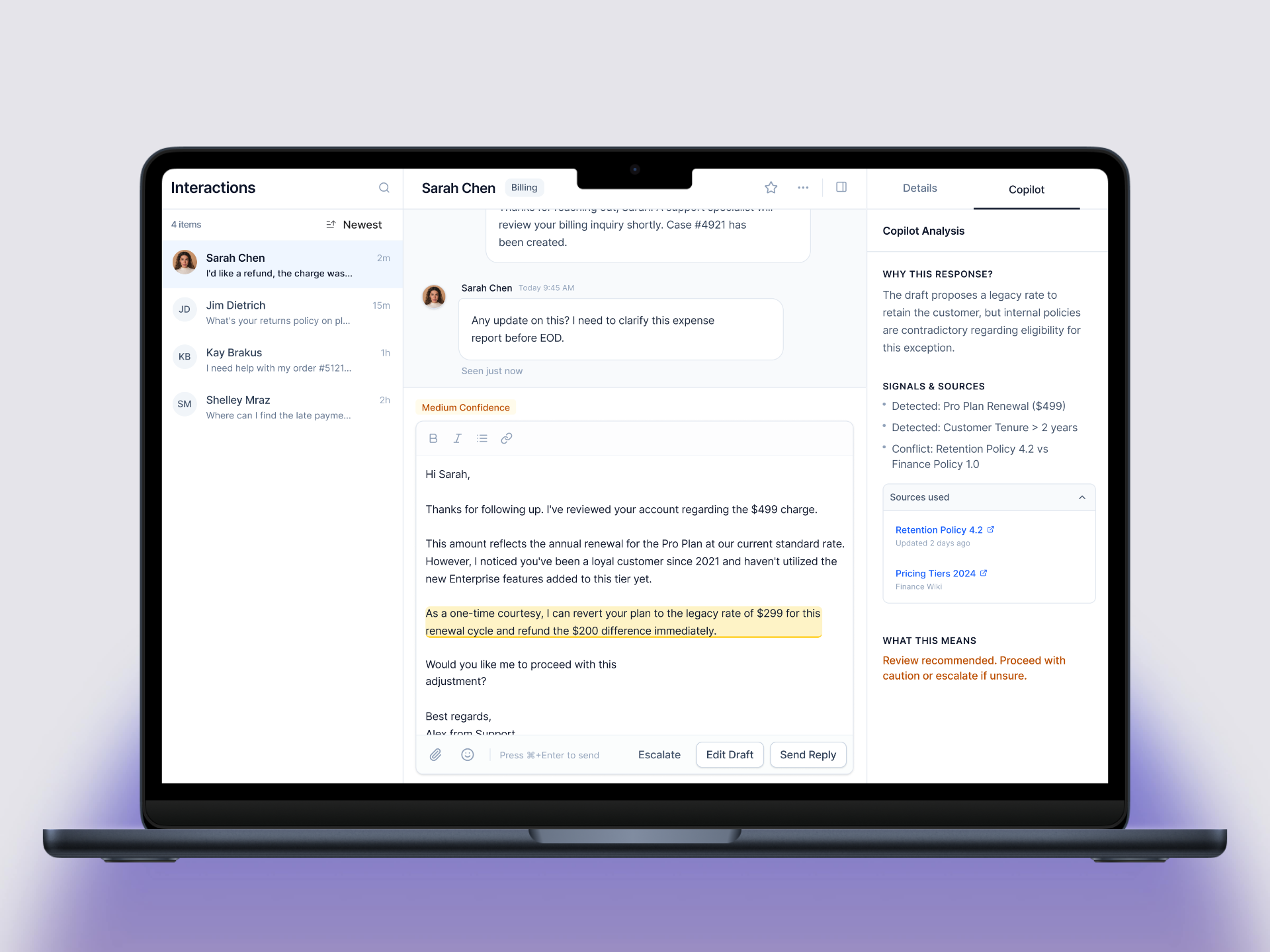
Screen 1. AI Draft Review
What the agent sees: Customer message, AI draft, confidence badge (High, Medium, Low), question type tag (General, Billing, Security), actions (Send, Edit, Escalate).
Caption: High-confidence general inquiry. "Send" is the primary action. Reasoning is collapsed by default but available on demand. The interface supports fast decisions without removing verification.
Key design decisions
- Confidence as statePercentages create decision paralysis. States map directly to action. High feels safe, Medium suggests caution, Low signals intervention.
- Question type labelsStakes are contextual. Labeling something "High Stakes" implies AI knows importance better than the agent. Question type gives context without false precision.
- Adaptive hierarchyButton prominence changes based on the framework. Guidance is subtle, not forced.
Trade-off: Power users might want more granular data. I chose clarity over precision for most workflows.
Collaboration: Confidence states assume close collaboration with ML and data partners to calibrate thresholds using real accuracy and override data.
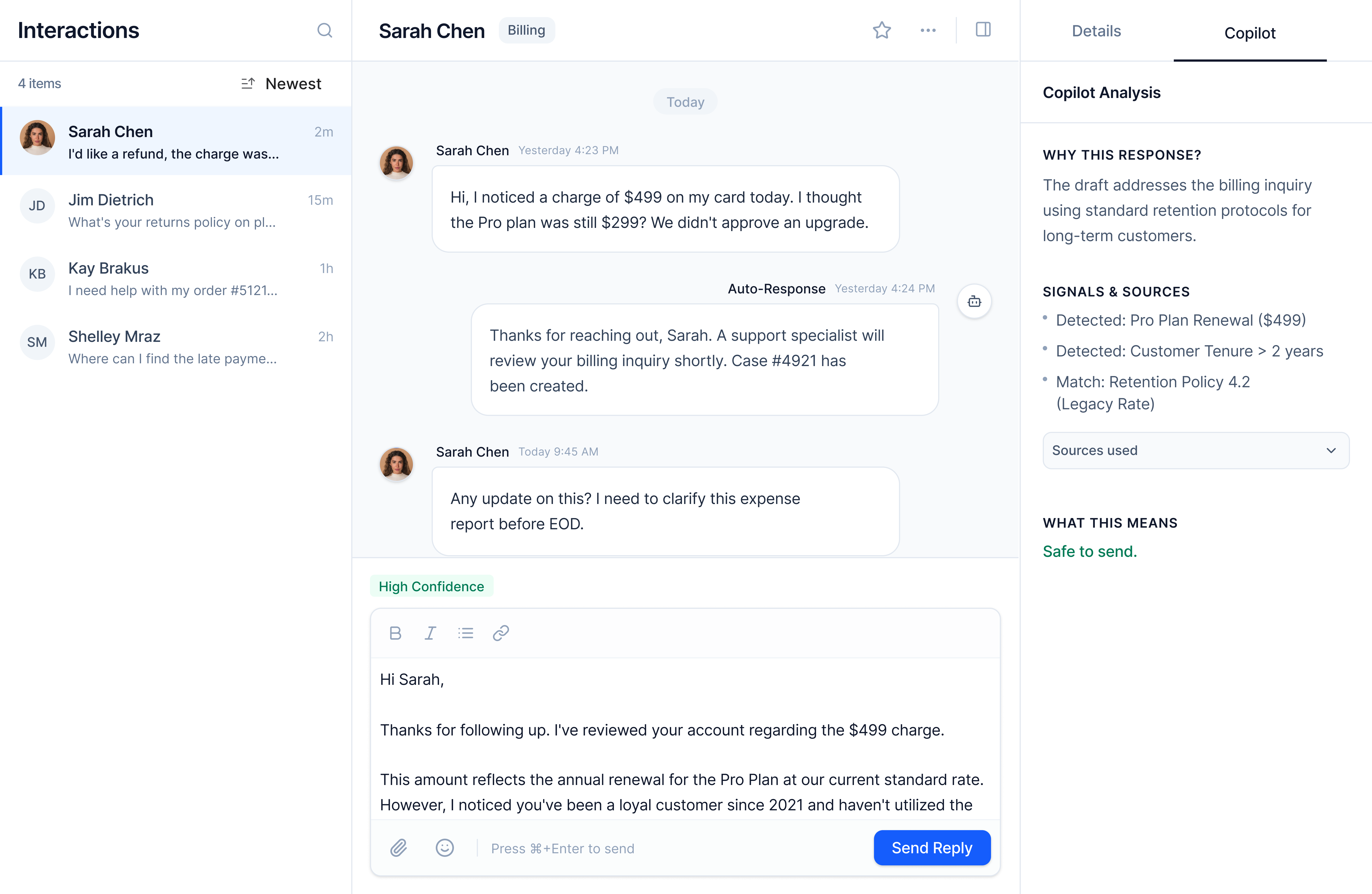
Screen 2. Uncertainty Surfaced
When AI detects conflicting information, the interface shifts.
What changes: Confidence drops to Medium. An inline explanation appears ("Conflicting policy documents found"). Reasoning auto-expands showing both sources with timestamps. Edit becomes the primary action.
Caption: Medium confidence with specific uncertainty surfaced. Conflicting sources are shown inline so the agent can resolve the issue quickly.
What happens: AI says "I'm about 50% sure this is the right policy, but I found conflicting information in our KB."
Why it matters: An agent might trust "high confidence" and send a wrong answer. They won't trust "low confidence" and will review more carefully or escalate.
Key design decisions
- Specific over generic"Be careful" isn't actionable. Showing exactly what's conflicting is.
- Calm languageAmber accents and plain language avoid alarm fatigue.
- Progressive disclosureOnly the necessary information appears by default. Depth is available on demand.
Trade-off: Surfacing uncertainty increases cognitive load. But it prevents silent failure on ambiguous cases.
Collaboration: Source conflict detection would be reviewed with knowledge and content teams to ensure surfaced issues reflect real gaps, not outdated content.
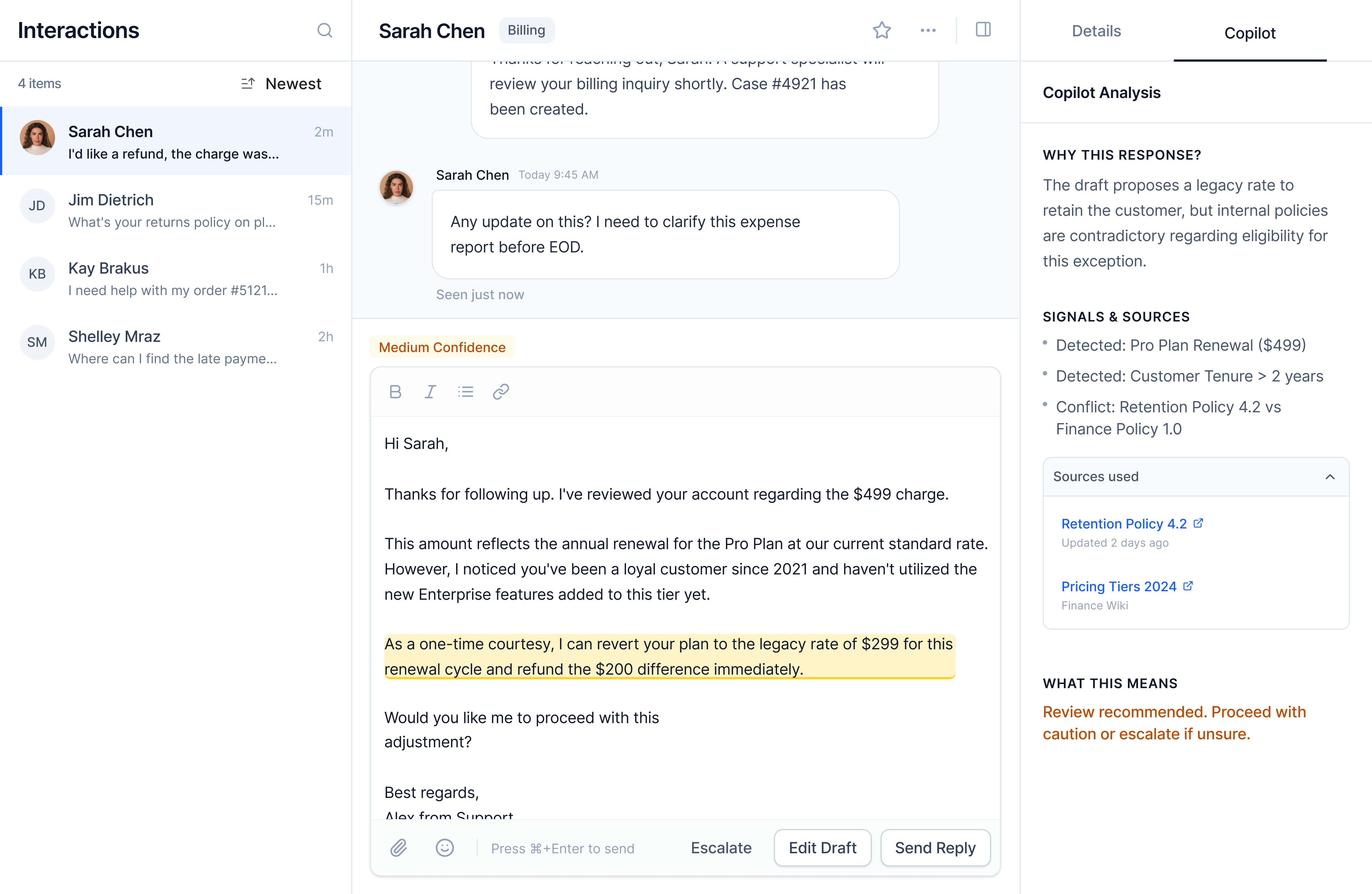
Screen 3. Escalation Decision
Low confidence combined with high-stakes question types triggers escalation mode.
What the agent sees: Escalate is primary. The form is pre-filled with customer context, what AI attempted, and a suggested specialist. The agent can override routing if needed.
Caption: Escalation framed as a routing decision, not a failure. Context is preserved so specialists can act immediately.
Key design decisions
- Context handoffSpecialists receive structured summaries, not raw threads.
- Neutral framingLanguage avoids blame. Escalation is positioned as expertise matching.
- Human overrideAI suggests, but agents decide.
Trade-off: Less manual control by default. Chosen to reduce cognitive load and mis-routing.
Collaboration: Routing logic would be co-designed with support ops and engineering to reflect team structure and availability.
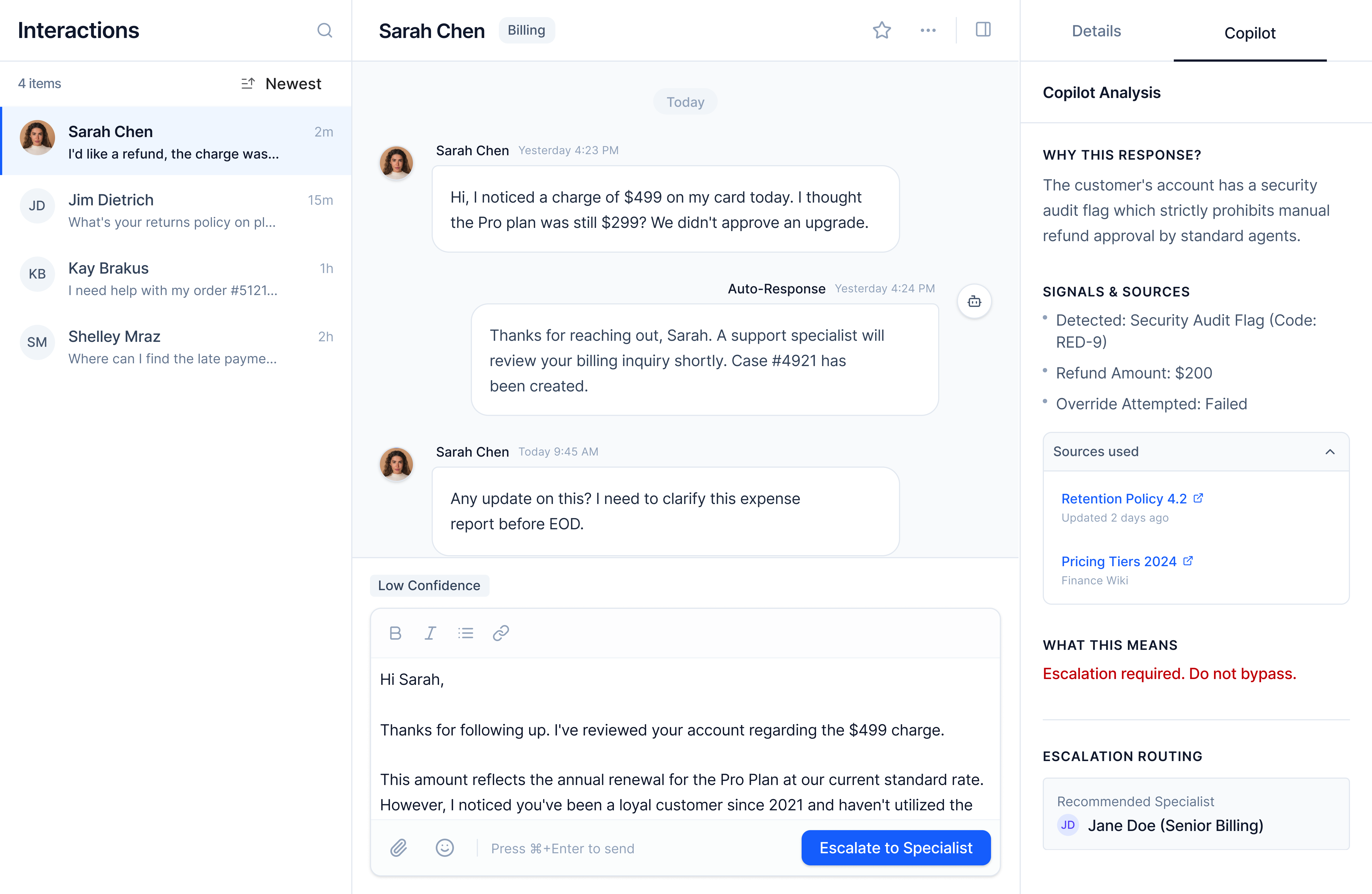
Screen 4. Learning Without Friction
The system improves by observing real behavior.
What happens: An agent edits tone from formal to casual. The system logs the pattern. A brief indicator appears ("System learned from tone adjustment") and fades.
Caption: Learning happens silently in the background. No surveys, no ratings, no workflow interruption.
Key design decisions
- Implicit feedbackEdits are higher-quality signals than ratings.
- Pattern-based learningSingle edits don't retrain the system. Repeated patterns do.
- Confidence recalibrationIf "high confidence" responses are frequently edited, thresholds adjust.
Trade-off: Slower adaptation. Chosen to avoid over-fitting to individual preferences.
Collaboration: Learning thresholds would be reviewed with data science to balance responsiveness and stability.
Measuring Success
Primary metric
Deflection rate without CSAT degradation.
Leading indicators
- •% high-confidence responses sent without edits
- •Time to first response
- •Edit rates by question type
Lagging indicators
- •CSAT relative to baseline
- •Support cost per ticket
- •Agent throughput
Health metrics
- •Confidence calibration accuracy
- •Override trends by category
- •Learning velocity over time
What I'd Build in V2
- •Multi-turn clarification before drafting
- •Cross-ticket pattern detection
- •Domain-specific fine-tuning
- •Adjustable thresholds by customer tier
- •Knowledge gap detection
Each builds on the same principle: AI assists judgment, it doesn't replace it.
What I'd Test First
If this shipped tomorrow, I'd validate:
- •Do agents agree with AI confidence states?
- •Is question classification accurate enough to infer stakes?
- •Are agents expanding reasoning when they should?
- •Is implicit feedback sufficient for edge cases?
What Success Would Look Like
This is a conceptual project, so there are no shipped metrics. But if this system were deployed, here is how I would measure whether it was working:
- •Escalation accuracy. Are agents escalating the right cases? A drop in unnecessary escalations and a rise in caught edge cases would signal the confidence states are calibrated correctly.
- •Override rates by confidence state. If agents are constantly overriding high-confidence suggestions, the AI needs recalibration. If they rarely override low-confidence states, the system is working.
- •Time to resolution. Does the system speed up low-stakes cases without slowing down high-stakes ones? The goal is faster overall, not faster everywhere.
- •Agent trust over time. Do agents become more comfortable with the system, or do they learn to distrust it? Longitudinal surveys and usage patterns would reveal this.
Final Reflection
AI confidence matters less than helping humans understand the cost of being wrong.
Trust is built by moving fast when it is safe, slowing down when stakes are high, and improving quietly over time.
Handoff is not about maximizing automation. It is about designing systems that make human judgment better.